Using Neural Networks to solve Classification Problems
The classification Neural Networks task builds a feed-forward neural network (NN) for classification. NN is a model that includes a certain number of elementary perceptrons organized in layers.
Each perceptron returns sigmoidal function (activation function) that depends on a weighted sum of its input. To retrieve the optimal weight vector for each perceptron a back-propagation algorithm is employed.
The output of the task is a model, consisting in a weight matrix ,that can be employed by an Apply Model task to perform the NN forecast on a set of examples.
Prerequisites
you must have created a flow;
the required datasets must have been imported into the flow;
the data used for the analysis must have been well prepared;
a single unified dataset must have been created by merging all the datasets into the flow.
Additional tabs
The Monitor tab, where it is possible to view the temporal evolution of some quantities related to the network optimization. In particular, the behavior of error, gradient and misclassification is reported as a function of the number of iterations. These plots can be viewed during and after computation operations.
The Weights tab, where it is possible to view the weight matrix for each hidden layer. The layer to be displayed can be selected from the Chose Layer drop down list. Each row in the spreadsheet represents a neuron, while each column corresponds to an input attribute.
The Results tab, where statistics on the NN computation are displayed, such as the execution time, number of rules, average covering etc.
Procedure
Drag the Neural Networks task onto the stage.
Connect a task, which contains the attributes from which you want to create the model, to the new task.
Double click the Neural Networks task. The left-hand pane displays a list of all the available attributes in the dataset, which can be ordered and searched as required.
Configure the options described in the table below.
Save and compute the task.
Neural Networks basic options | |
Parameter Name | Description |
|---|---|
Input attributes | Drag and drop here the input attributes you want to use to build the network. Instead of manually dragging and dropping attributes, they can be defined via a filtered list. |
Output attributes | Drag and drop here the output attributes you want to use to build the network. Instead of manually dragging and dropping attributes, they can be defined via a filtered list. |
Number of hidden layers | The number of hidden layers in the network. |
Neurons for each hidden layer | The number of neurons in each hidden layer. This option is enabled only if the value specified for the Number of hidden layers option is greater than zero. |
Learning rate | Indicate the coefficient of the gradient descent. For high values it is likely that the algorithm converges more quickly, but it may lack in precision. Alternatively, with low learning rates, the algorithm will converge more slowly, but with more accuracy. |
Momentum term | Specify the momentum of the back-propagation algorithm. Momentum adds a fraction (between 0 and 1) of the previous weight update to prevent the system from converging to a local minimum. |
Normalization for input attributes | The type of normalization to use when treating ordered (discrete or continuous) variables. Possible methods are:
Every attribute can have its own value for this option, which can be set in the Data Manager task. These choices are preserved if Attribute is selected in the Normalization of input variables option; otherwise any selections made here overwrite previous selections made. |
Normalization of output attributes | Select the method for normalizing output variables, in the same way as the Normalization for input variables. |



Neural Networks advanced options | |
Parameter Name | Description |
|---|---|
Maximum number of iterations | The maximum number of iterations allowed for the gradient descent algorithm for each trial. |
Number of trials | Select the number of trials, i.e. the repeated execution of back-propagation algorithm, with different starting conditions. |
Maximum number of iterations for any trial | The maximum number of iterations allowed for the gradient descent algorithm for each trial. |
Initialize random generator with seed | If selected, a seed, which defines the starting point in the sequence, is used during random generation operations. Consequently using the same seed each time will make each execution reproducible. Otherwise, each execution of the same task (with same options) may produce dissimilar results due to different random numbers being generated in some phases of the process. |
Use symmetric activation function | If selected, use an activation function in the range (-1,1) instead of (0,1). |
Append results | If selected, the results of this computation are appended to the dataset, otherwise they replace the results of previous computations. |
Aggregate data before processing | If selected, identical patterns are aggregated and considered as a single pattern during the training phase. |
Example
The following example uses the Adult dataset.
Description | Screenshot |
|---|---|
After having imported the dataset with the Import from Text File task and splitting the dataset into test and training sets (30% test and 70% training) with the Split Data task, add a Neural Networks to the flow and configure the NN task as follows:
Leave the other options with their default values and compute the task. | 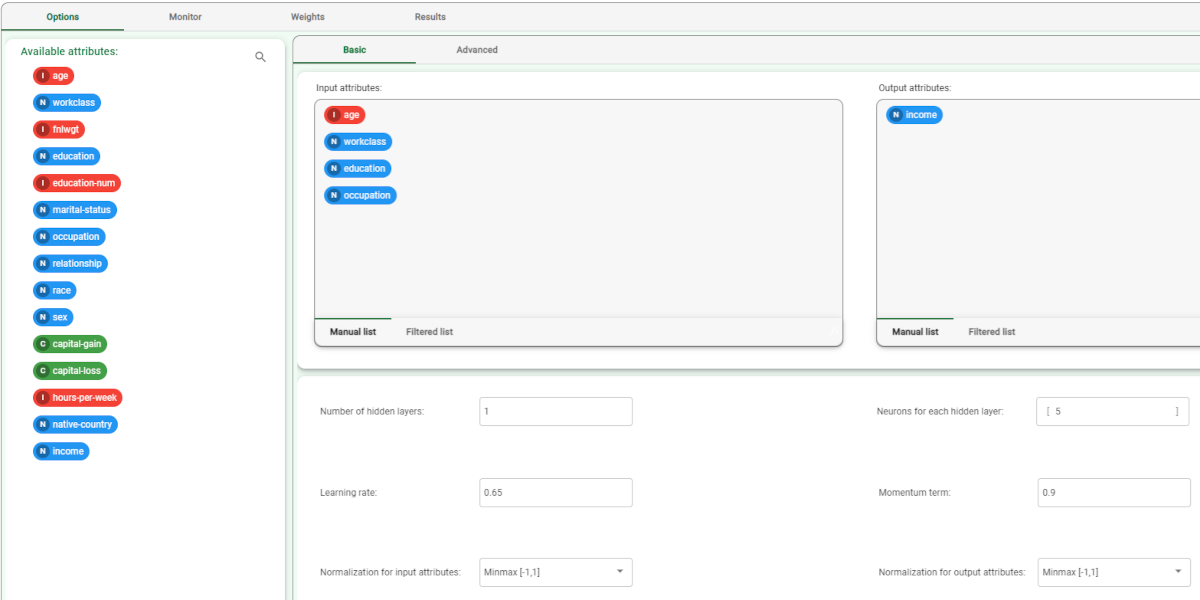
|
The execution of the task can be monitored in the Monitor tab of the NN task. In these plots the behavior of the error as a function of the iteration is showed. Analogous plots can be visualized for gradient and misclassified by clicking on the corresponding tabs. | 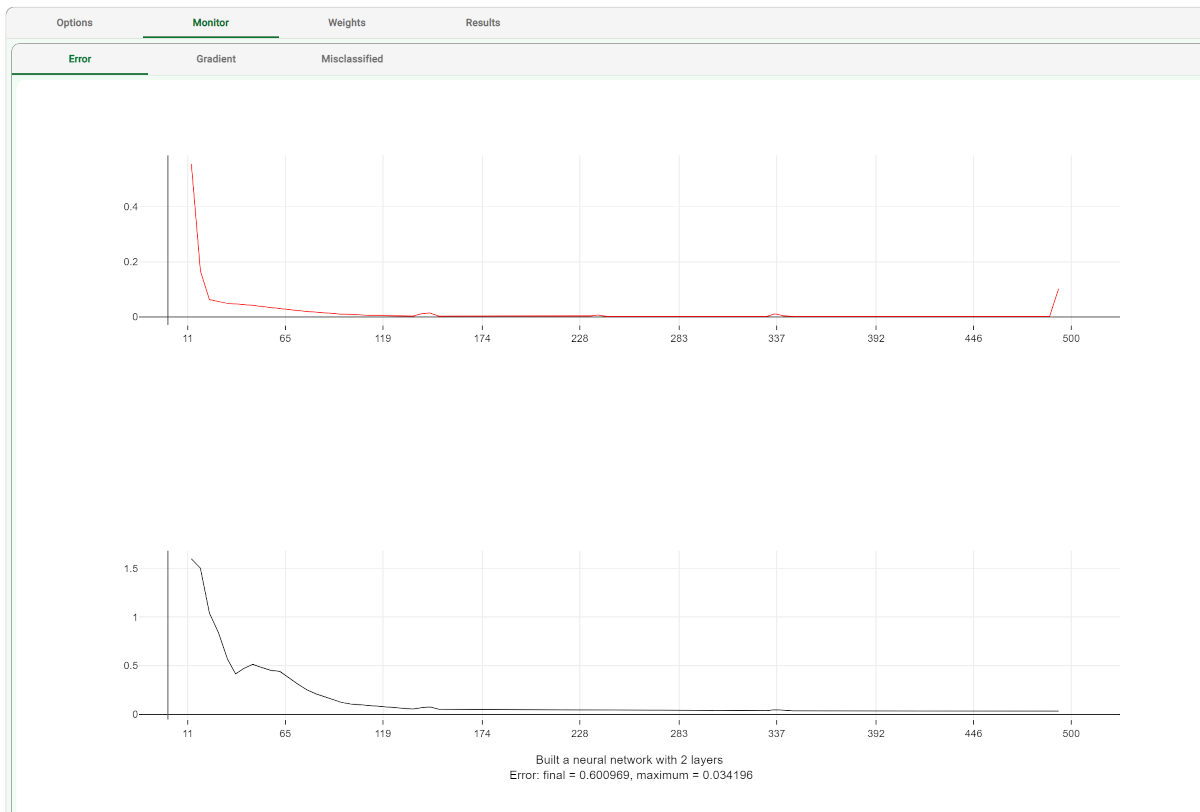 |
Clicking on the Weights tab at the end of the execution, displays the weights obtained through the optimization procedure. The layer to be visualized can be selected in the Select a layer drop-down list: Each row corresponds to a neuron of that layer and contains the weights relative to each input attribute. The first column contains the bias, i.e. the constant term in the linear combination of inputs. |  |
The Results tab contains a summary of the computation. |  |
The forecast ability of the set of generated rules can be viewed by adding an Apply Model task to the Neural Networks task, and computing with default options. |  |
The forecast produced by the Apply Model task can be analyzed by right-clicking the task and selecting Take a look. In the data table the following columns relative to the results of the elaboration have been added:
| 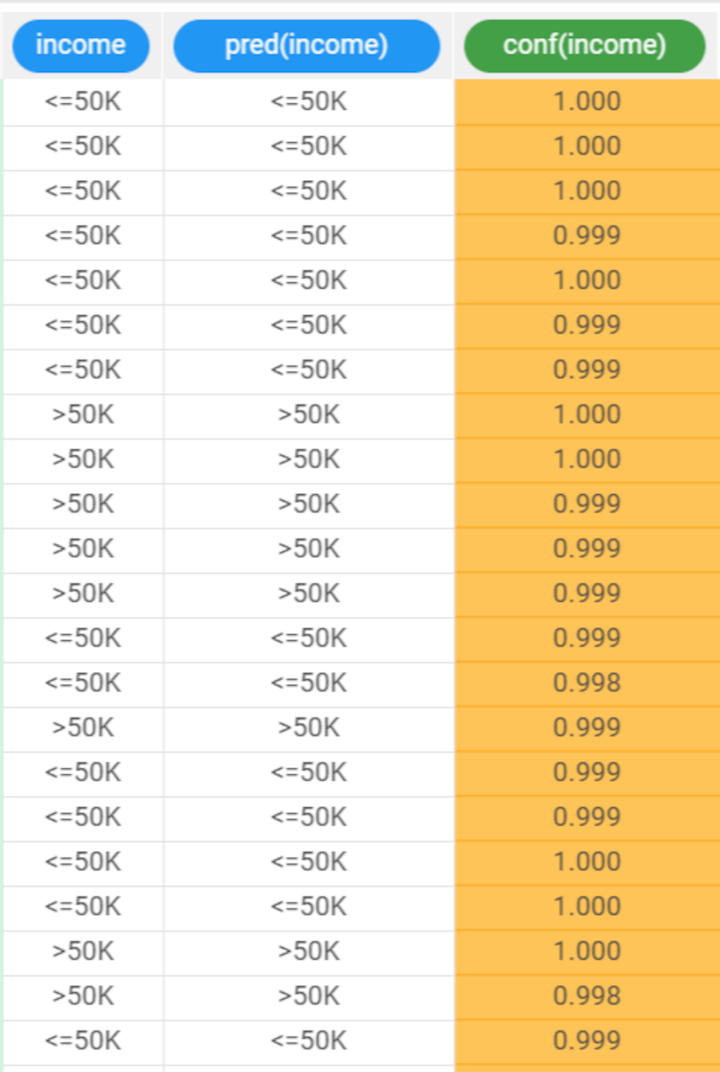 |
Selecting Test Set from the Displayed data drop down list shows how the rules behave on new data. | 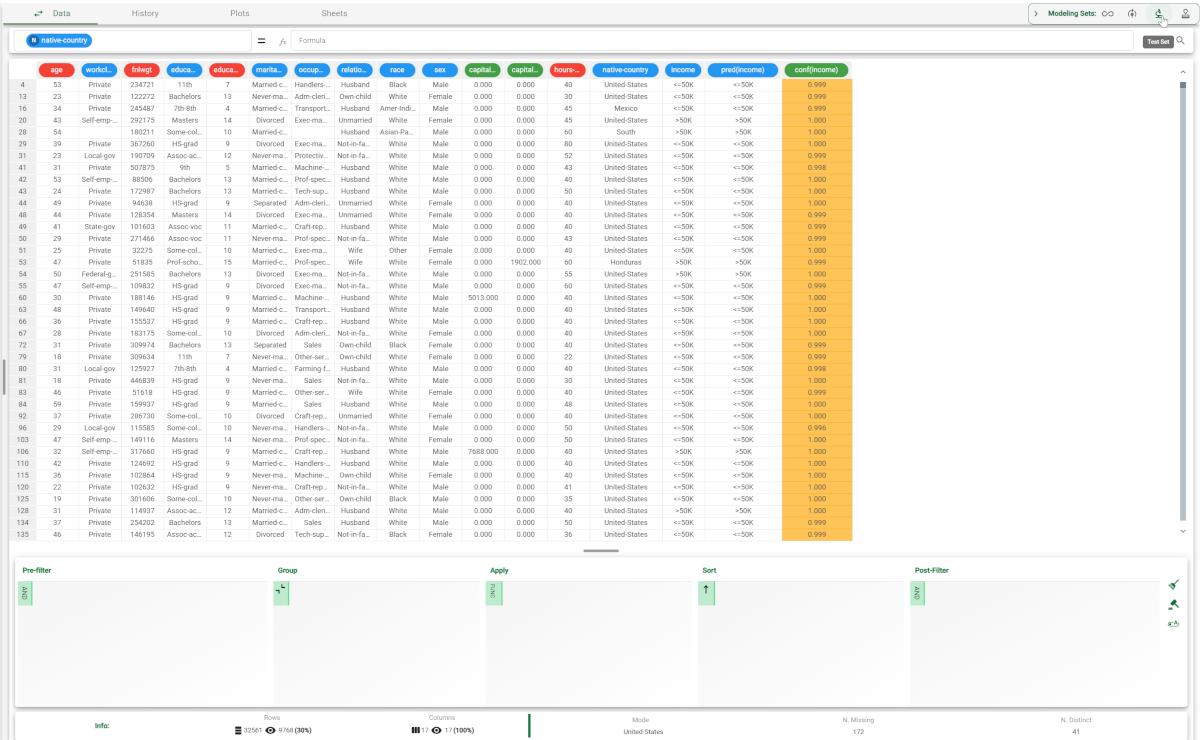 |
