Concatenating datasets
The Concatenate task in Rulex merges datasets by their columns, creating a single table with all the data.
There is no limit on the number of datasets you can concatenate.
Prerequisites
You must have created a flow;
The required datasets must have been imported into the flow.
Procedure
Drag the Concatenate task onto the stage.
Connect the tasks that contain the datasets you want to merge to merge the Concatenate task. The order in which data is displayed in the final table depends on the order in which the import tasks are connected to the Concatenate task.
Double click the Concatenate task.
Select the Concatenation type (cattype) you require from the drop-down list:
inner (cattype = 0), where only attributes present in both tables are included in the final merged table
outer (cattype = 1), where all attributes are copied, filling in any missing values if necessary.
Select how you want to match columns from the Match column by (byname) drop-down list, either by
position (byname = 0), where attributes in the same position are considered equal
name (byname = 1), where attributes with the same name are considered equal.
Save and compute the task.
Example
The following example uses the Northwind datasets.
Description | Screenshot |
|---|---|
In the example here, after having imported the datasets, drag the Concatenate task onto the stage and link it to the datasets. The first dataset contains 830 rows, while the second one 415. | 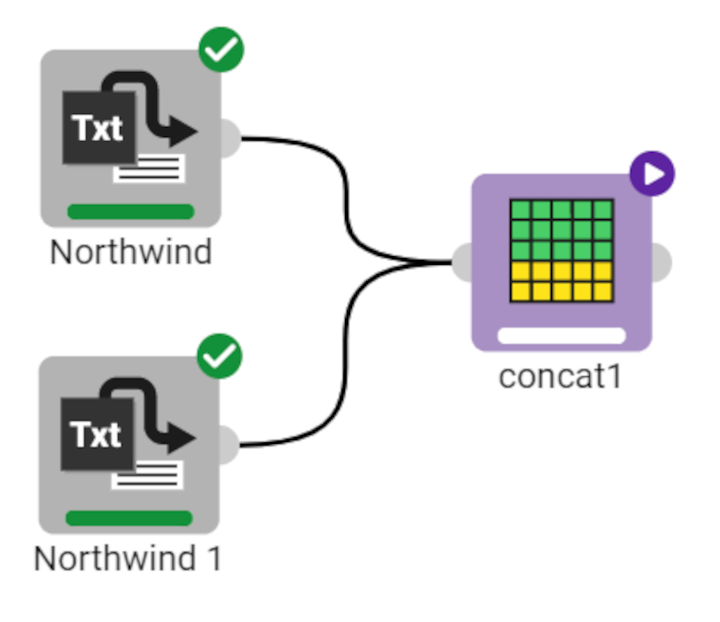 |
Double click the task to open it. Select inner concatenation, matching the attributes by name. Then, save and compute the task. | 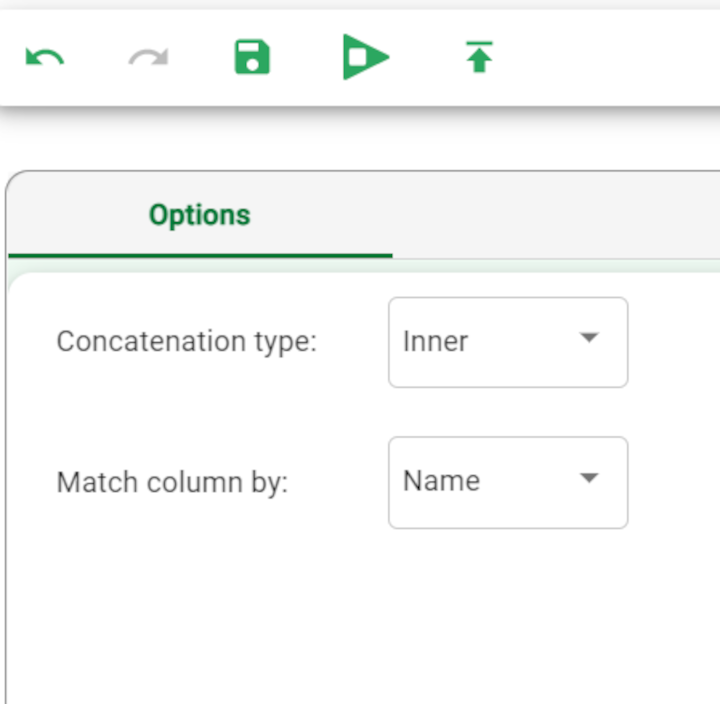 |
Right click on the task to see the results and click Take a look: there are 1245 rows in the dataset now, that correspond to the sum of the two previous datasets, that is 830+415. | 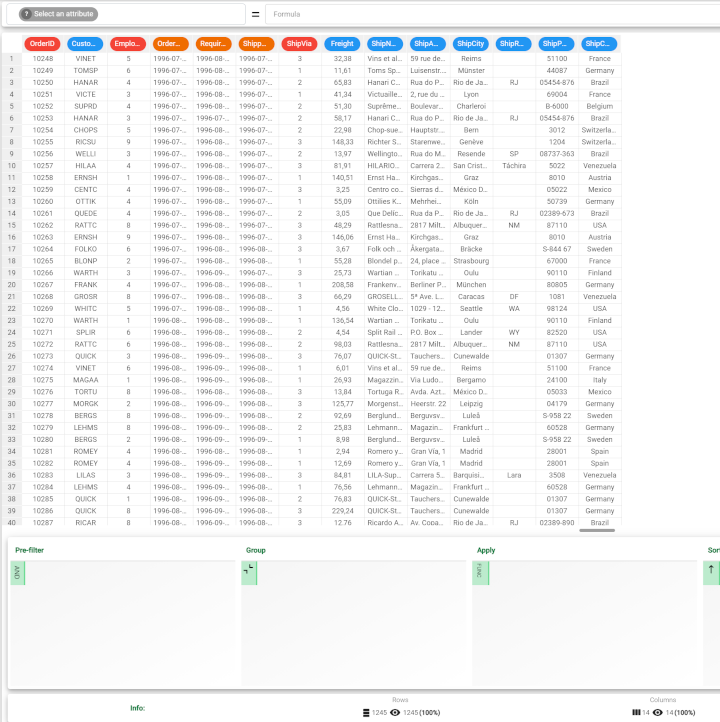 |