Using LLM to solve Regression Problems
Rulex solves regression problems with the Regression Logic Learning Machine task (LLM).
This task accurately predicts continuous variables, for example, predicting the price of goods, given a set of input attributes on market conditions, through predictive intelligible logic based rules.
Prerequisites
you must have created a flow;
the required datasets must have been imported into the flow;
the data used for the analysis must have been well prepared;
a unified model must have been created by merging all the datasets in the flow.
Additional tabs
The Monitor tab, where it is possible to view the statistics related to the generated rules as a set of histograms, such as the number of conditions, covering value, or error value. Rules relative to different classes are displayed as bars of a specific color. These plots can be viewed during and after computation operations.
The Results tab, where statistics on the LLM computation are displayed, such as the execution time, number of rules, average covering etc.
Procedure
Drag the Logic Learning Machine task onto the stage.
Connect a task, which contains the attributes from which you want to create the model, to the new task.
Double click the Logic Learning Machine task. The left-hand pane displays a list of all the available attributes in the dataset, which can be ordered and searched as required.
Configure the options described in the table below.
Save and compute the task.
Regression LLM Basic options | |
Parameter Name | Description |
|---|---|
Input attributes | Drag and drop here the input attributes you want to use to form the rules leading to the correct classification of data. Instead of manually dragging and dropping attributes, they can be defined via a filtered list. |
Output attributes | Drag and drop here the attributes you want to use to form the final classes into which the dataset will be divided. Instead of manually dragging and dropping attributes, they can be defined via a filtered list. |
Key attributes | Drag and drop here the key attributes. Key attributes are the attributes that must always be taken into consideration in rules, and every rule must always contain a condition for each of the key attributes. Instead of manually dragging and dropping attributes, they can be defined via a filtered list. |
Number of rules for each class (0 means 'automatic') | The number of rules for each class. If set to 0 the minimum number of rules required to cover all patterns in the training set is generated. |
Minimum rule distance for additional rules | The minimum difference between additional rules, taken into consideration if the Prevent rules in input from being included in the LLM model option has been selected. |
Maximum number of conditions for a rule | Set the maximum number of conditions in a rule. |
Maximum nominal values | Set the maximum number of nominal values that can be contained in a condition. This is useful for simplifying conditions and making them more manageable, for example when an attribute has a very high number of possible nominal values. It is worth noting that overly complicated conditions also run the risk of over-fitting, where rules are too specific for the test data, and not generic enough to be accurate on new data. |
Maximum error allowed for each rule (%) | Set the maximum error (in percentage) that a rule can score. The absolute or relative error is considered according to the whether the Consider relative error instead of absolute option is checked or not. |
Minimum interval for a condition on ordered attribute (%) |
|
Consider relative error instead of absolute | Specify whether the relative or absolute error must be considered. The Maximum error allowed for each rule is set by considering proportions of samples belonging to different classes. Imagine a scenario where for given rule pertaining to the specific output value yo:
In this scenario the absolute error of that rule is FP/(TN+FP), whereas the relative error is obtained as follows: FP/Min(TP+FN,TN+FP) (samples with the output value yo that do verify the conditions of the rule). |
Prevent interval conditions for ordered attributes | If selected, interval conditions, such as 1<x≤5, are avoided, and only conditions with > (greater than) ≤ (lower or equal than) are generated. |
Regression LLM Advanced options | |
Parameter Name | Description |
|---|---|
Minimize number of conditions | If selected, rules with fewer conditions, but the same covering, are privileged. |
Ignore attributes not present in rules | If selected, attributes that have not been included in rules will be flagged Ignore at the end of the training process, to reflect their redundancy in the classification problem at hand. |
Hold all the generated rules | If selected, even redundant generated rules, which are verified only by training samples that already covered by other more powerful rules, are kept. |
Aggregate data before processing | If selected, identical patterns are aggregated and considered as a single pattern during the training phase. |
Missing values verify any rule condition | If selected, missing values will be assumed to satisfy any condition. If there is a high number of missing values, this choice can have an important impact on the outcome. |
Perform a coarse-grained training (faster) | If selected, the LLM training algorithm considers the conditions with the subset of values that maximizes covering for each input attribute. Otherwise, only one value at a time is added to each condition, thus performing a more extensive search. The coarse-grained training option has the advantage of being faster than performing an extensive search. |
Use median as output value | If selected, the median of the output attribute will be calculated and displayed as values in the output attribute. |
Append results | If selected, the results of this computation are appended to the dataset, otherwise they replace the results of previous computations. |
Maximum number of trials in bottom-up mode | The number of times a bottom-up procedure can be repeated, after which a top-down procedure will be adopted. The bottom-up procedure starts by analyzing all possible cases, defining conditions and reducing the extension of the rules. If, at the end of this procedure, the error is higher than the value entered for the Maximum error allowed for each rule (%) option, the procedure starts again, inserting an increased penalty on the error. If the maximum number of trials is reached without obtaining a satisfactory rule, the procedure is switched to a top-down approach. |
Initialize random generator with seed | If selected, a seed, which defines the starting point in the sequence, is used during random generation operations. Consequently using the same seed each time will make each execution reproducible. Otherwise, each execution of the same task (with same options) may produce dissimilar results due to different random numbers being generated in some phases of the process. |
Overlap between rules (%) | Set the maximum percentage of patterns, which can be shared by two rules. |
Example
The following example uses the Adult dataset.
Description | Screenshot |
|---|---|
| 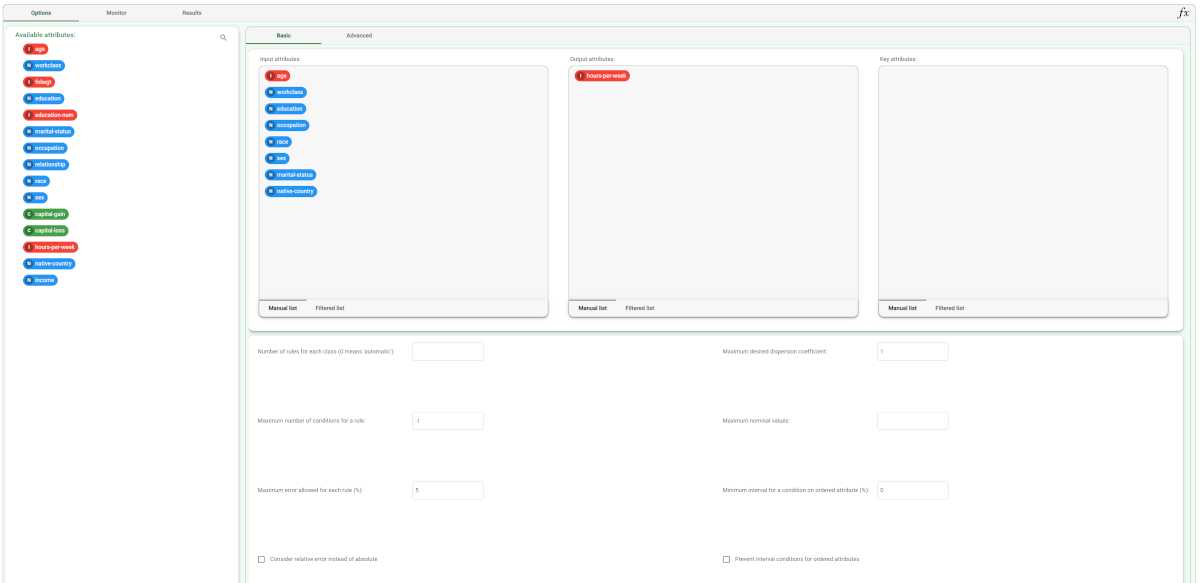 |
The distribution and properties of the generated rules can be viewed in the Monitor tab of the LLM task. The total number of rules, and the minimum, maximum and average of the number of conditions is reported, too. Analogous histograms can be viewed for covering and error, by clicking on the corresponding tabs. | 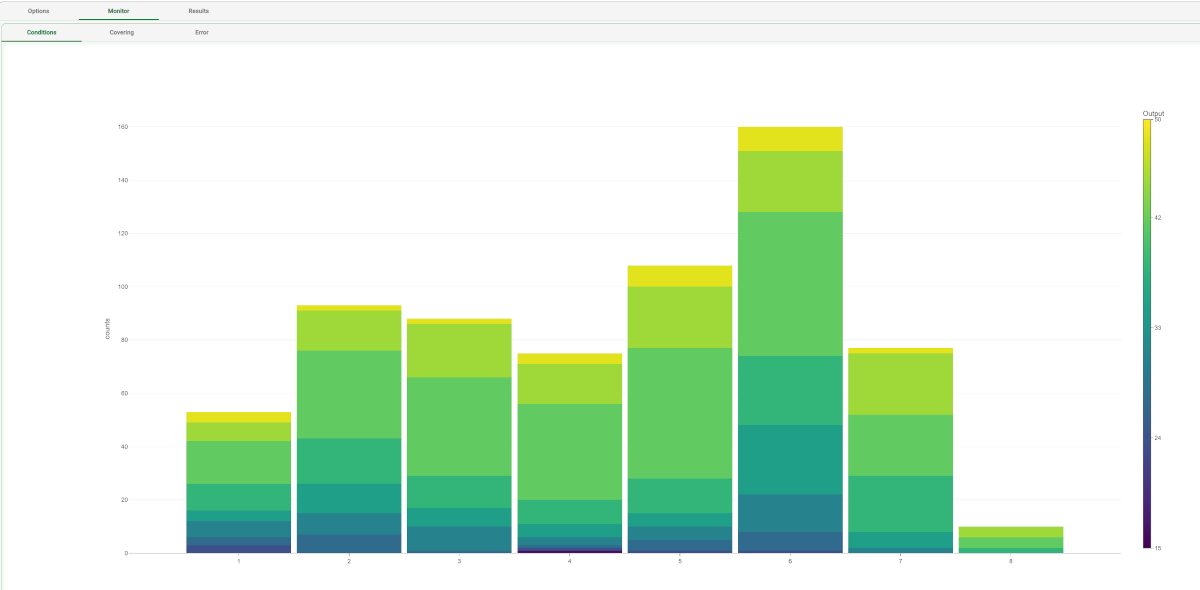 |
Clicking on the Results tab displays a great deal of information on the task, such as
| 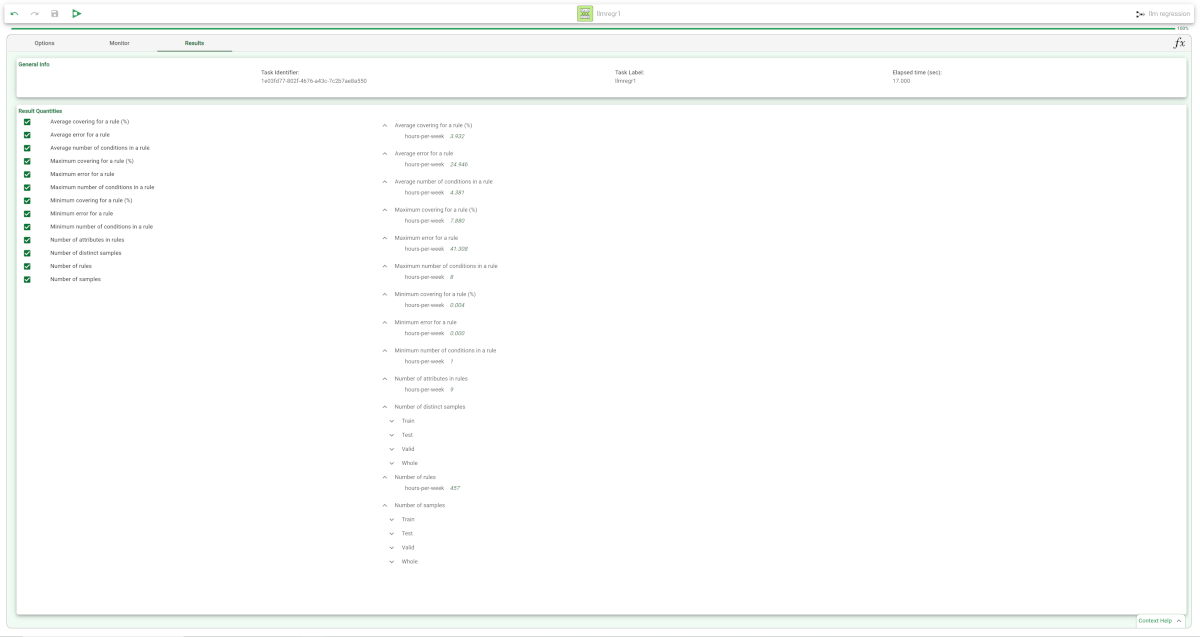 |
| 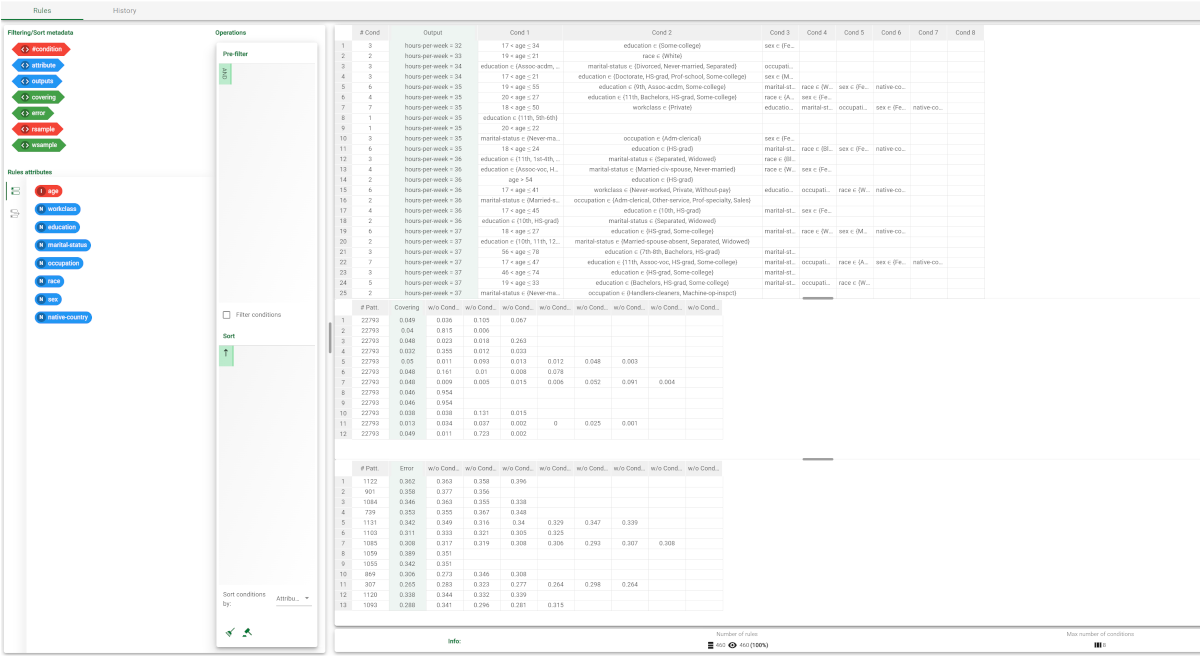 |
The forecast ability of the set of rules resulting from LLM can be viewed by adding an Apply Model task to the flow, and computing it with default values. | 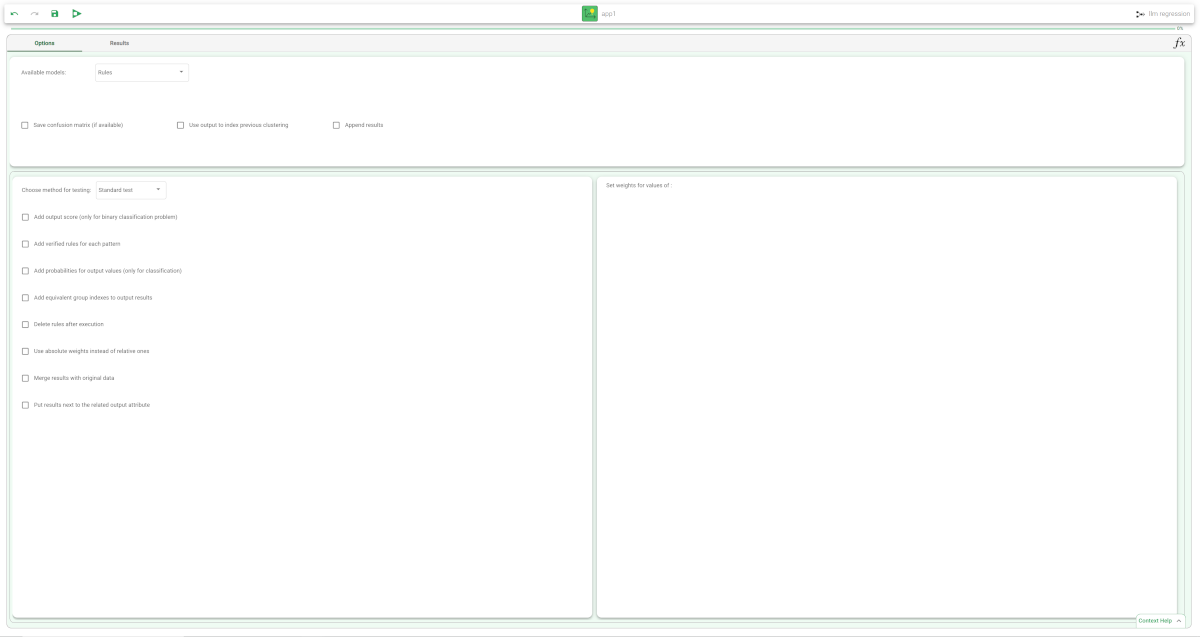 |
Right-click the computed Apply Model task and select Take a look, to check the results. Alternatively, you can add a Data Manager and link it to the Apply Model task. The following columns have been added to the data set:
| 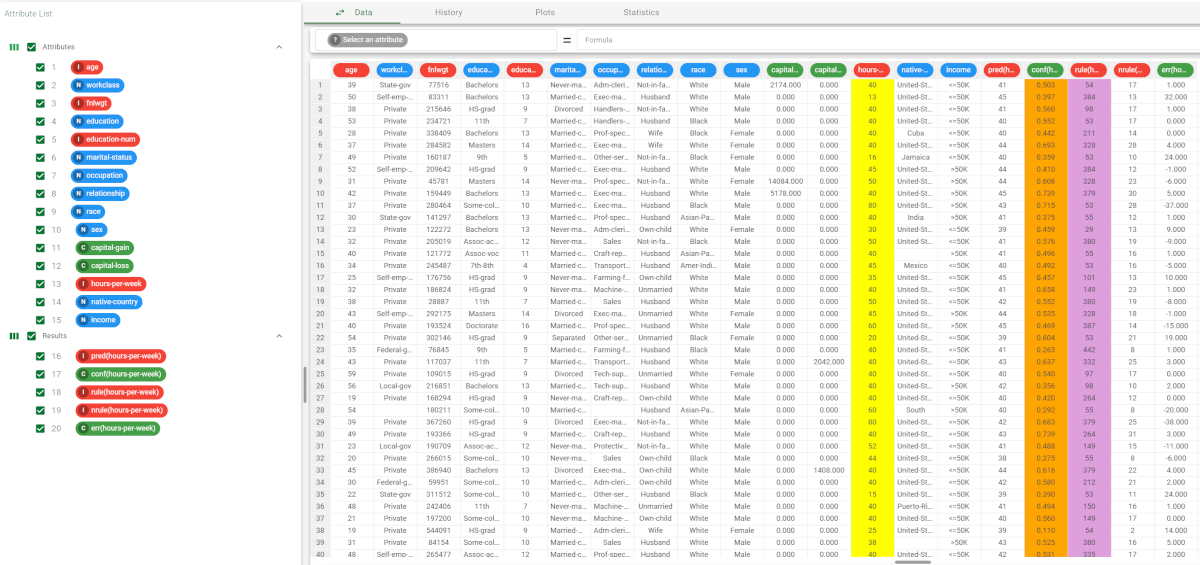 |
Selecting Test Set from the Displayed data drop down list shows how the rules behave on new data. In the test set, the value of | 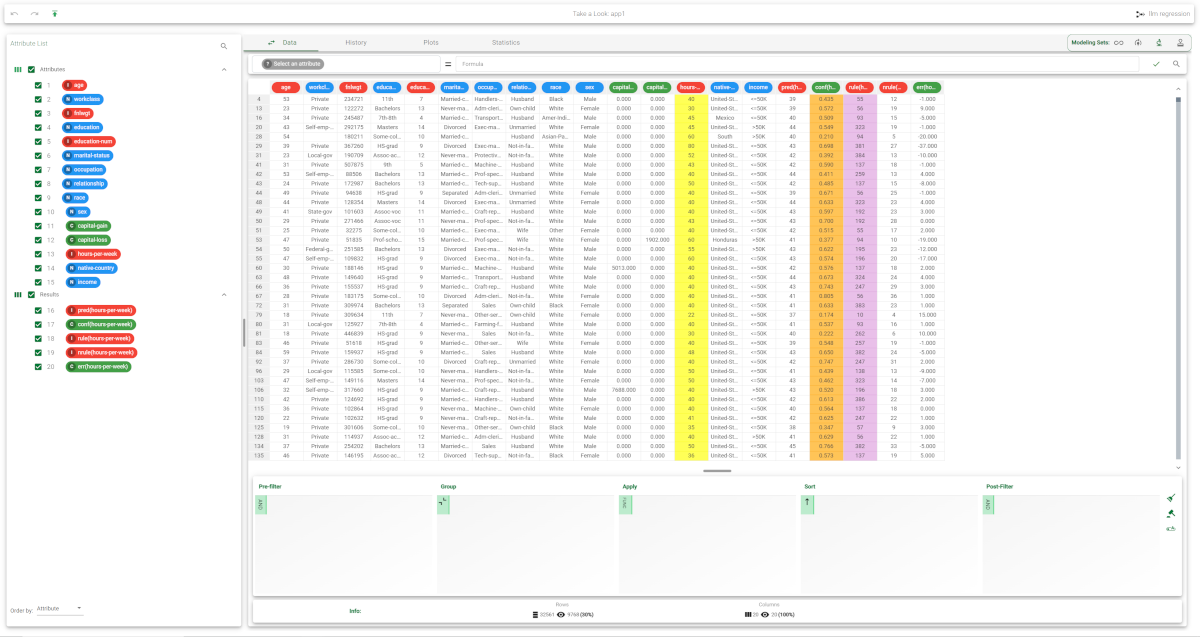 |