Splitting Data with the Split Data Task
The Split Data task divides the dataset into three subsets of patterns:
the training set, used to build the model,
the test set, used to assess the accuracy of the model and
the validation set, used for tuning the model parameters. The validation set is not mandatory.
Prerequisites
you must have created a flow;
the required datasets must have been imported into the flow;
the data must have been well prepared;
in case you are using more datasets, a single unified model must have been created by merging them.
Procedure
Drag the Split Data task onto the stage.
Connect the task that contains the dataset you want to split to the Split Data task.
Double click the Split Data task.
Configure the split options as described in the table below.
Save and compute the task.
Split options | |
|---|---|
Name | Description |
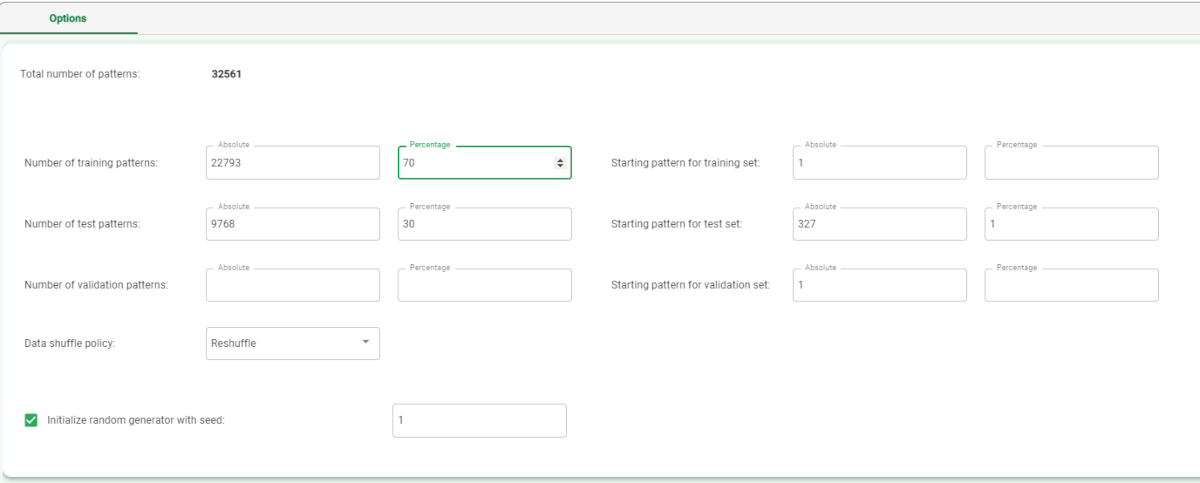
Number of training patterns | Indicate the number of training patterns, either as an absolute number of patterns or as a percentage of the overall dataset, which will be used to create the training set. These patterns are used to build the model. |
Starting pattern for training set | Indicate the starting point for the training set pattern either as an absolute value, or as a percentage of the whole. This option is valid only if No Shuffle is selected as the Data reshuffle policy. |
Number of test patterns | Indicate the number of test patterns, either as an absolute number of patterns or as a percentage of the overall dataset, which will be used to create the test set. These patterns are not used to build the model. |
Starting pattern for test set | Indicate the starting point for the test set pattern either as an absolute value, or as a percentage of the whole. This option is valid only if No Shuffle is selected as the Data reshuffle policy. |
Number of validation patterns | Indicate the number of validation patterns, either as an absolute number of patterns or as a percentage of the overall dataset, which will be used to create the validation set. The validation patterns cannot be used to create or test the model and are not mandatory as they are are used only for internal validation by some modeling methods. |
Starting pattern for validation set | Indicate the starting point for the validation set pattern either as an absolute value, or as a percentage of the whole. This option is valid only if No Shuffle is selected as the Data reshuffle policy. |
Data reshuffle policy | Indicate the required Data shuffle policy from the drop-down list:
|
Initialize random generator with seed | Select Initialize random generator with seed if you want to set the seed for the random generator. This may be useful to make each execution reproducible. Otherwise, each execution of the same task (with same options) may produce dissimilar results due to the different random numbers generated to define training/test/validation sets. |
Example
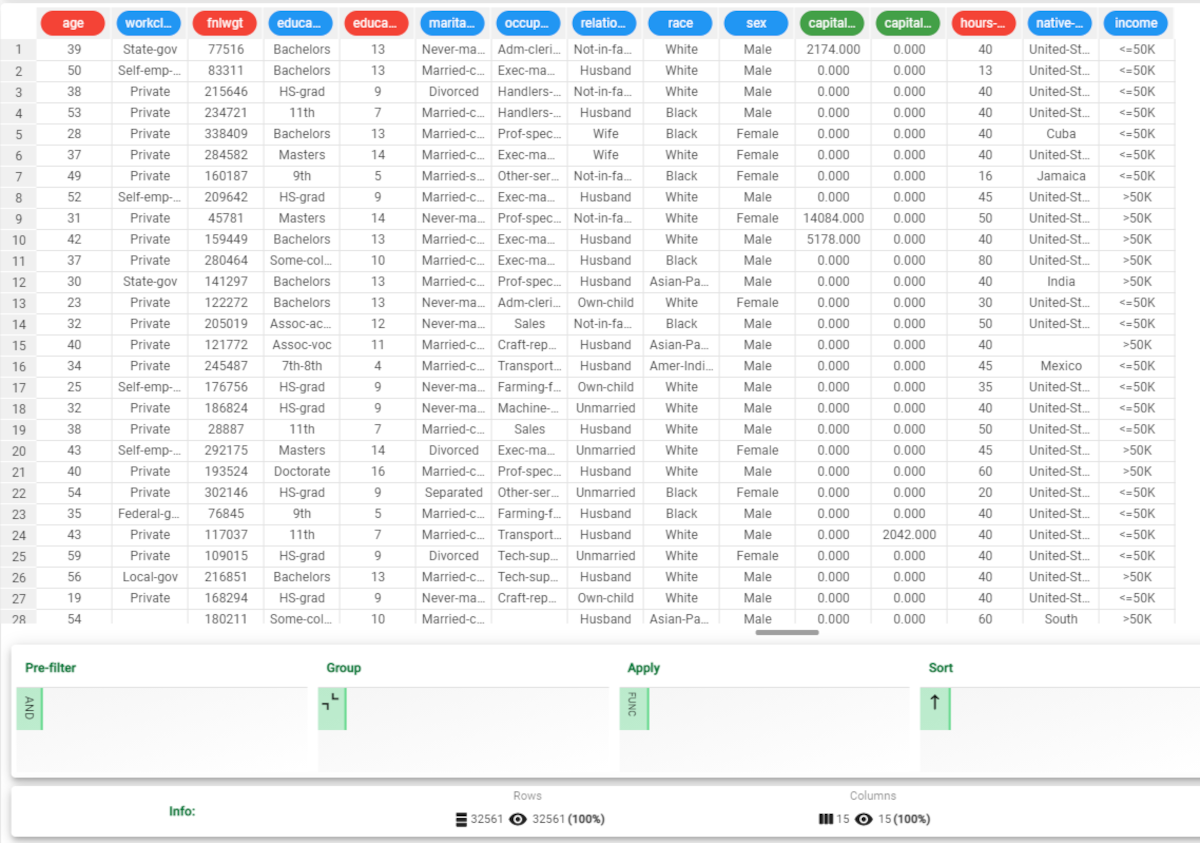
The following example uses the Adult dataset.
Description | Screenshot |
|---|---|
|  |
|  |
Add a Data Manager onto the stage and link it to the split data. In the Modeling Sets section, click on the Training set and the Test set to display the divided data. We will have:
|  |