Reshaping Datasets to Long Format
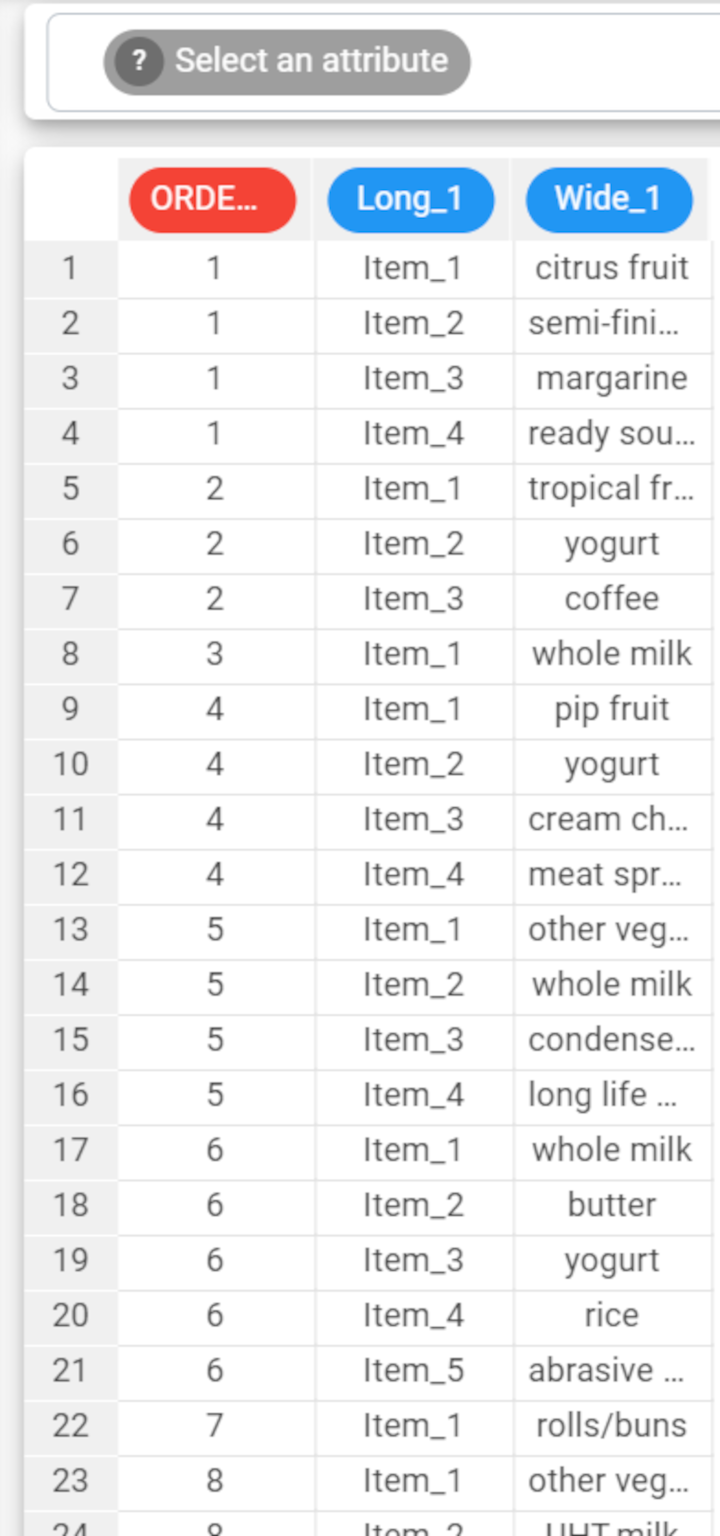
The reshape to long pivoting operation reshapes a dataset by transforming a set of similar attributes into a new pair of attributes, containing the name of the erased column and the value respectively.
Consequently the number of attributes in the dataset will be decreased and the number of rows will be increased accordingly.
Rulex reshaping operations are similar to creating pivot tables in Microsoft Excel, where you can create a new table with the structure you require by summarizing the data from the original table. However Rulex reshapes the original table without creating a second table, and the new table is structured automatically, increasing or decreasing the number of rows and columns, and repeating some rows to fit the new shape if necessary.
Prerequisites
you must have created a flow;
the required datasets must have been /wiki/spaces/RPDP/pages/2658467884.
Procedure
Drag the Reshape To Long task onto the stage.
Connect a task that contains the attributes you want to transform to the Reshape To Long task.
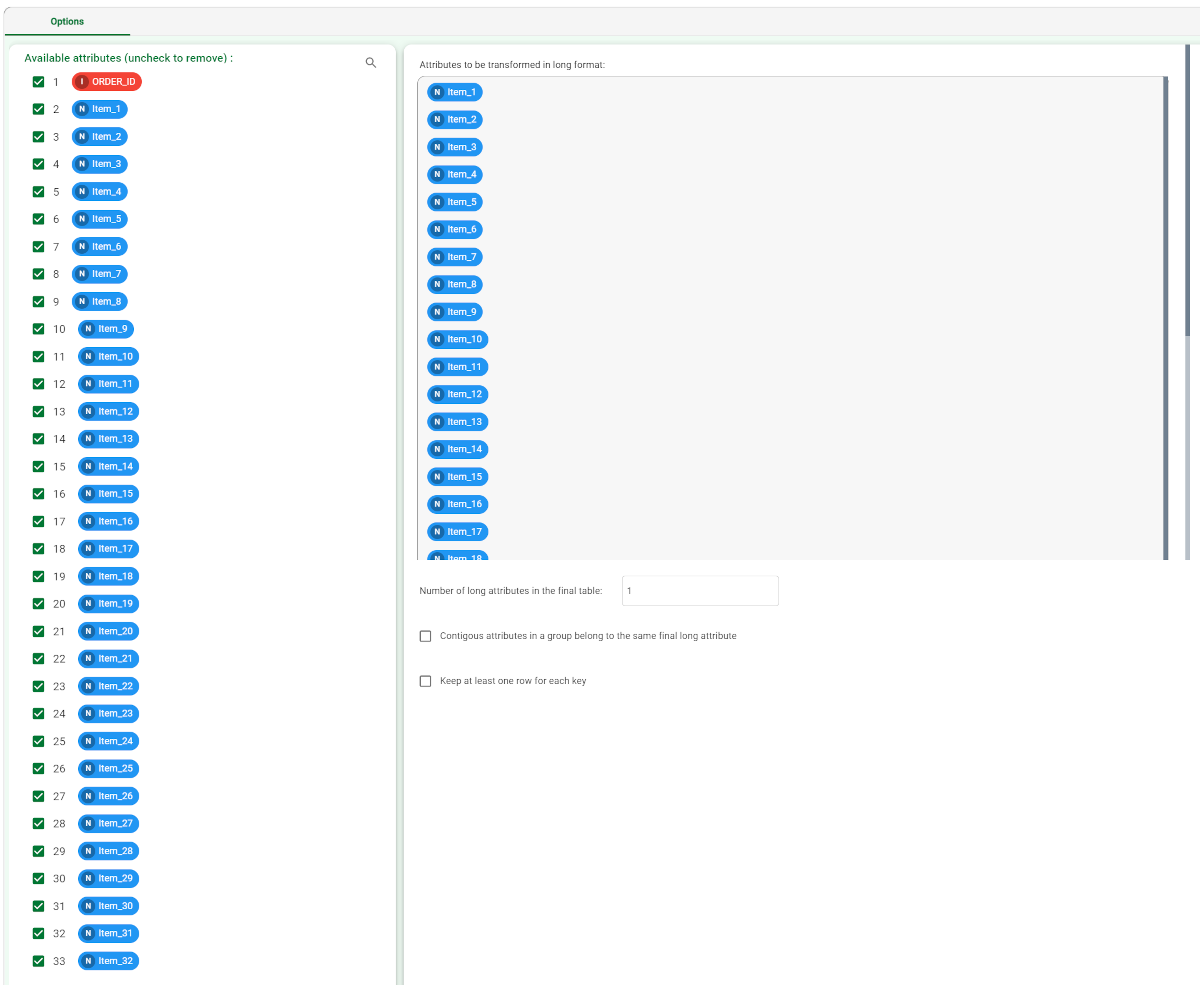
Double click the Reshape To Long task. The left-hand pane displays a list of all the available attributes in the dataset, which can be ordered and searched as required. Select the attributes that will be displayed in the final table.
Configure the task options as described in the table below.
Save and compute the task.
Reshape to Long options | |
Name | Description |
|---|---|
Attributes to be transformed in long format | Drag and drop the attributes that will become a single column in the resulting data table. Instead of manually dragging and dropping attributes, they can be defined via filtered list. |
Number of long attributes in the final table | Specify over how many columns the united values should be spread. By default, the values of all the Attributes to be transformed in long format are inserted in a single column (with an extra column specifying which attribute the value refers to). |
Contiguous attributes in a group belong to the same final long attribute | If selected, contiguous attributes will be used in the same final column, otherwise attributes are selected alternatively. |
Keep at least one row for each key | If selected, at least one row is displayed for each key, even if it contains, for example, only missing values. |
Example
The following example uses the groceries dataset.
Description | Screenshot |
|---|---|
|  |
|  |
|  |