cohenk function
The cohenk function applies the Cohen kappa’s coefficient to compare values. It is commonly used to compare real and predicted values to evaluate model performance, considering the probability of agreement by pure chance.
Its resulting value can range from 0 to 1:
0 corresponds to a totally random correspondence.
1 indicates complete correspondence between the values, and consequently indicative of best performance.
The value can also be negative, and it indicates a poor performance.
Parameters
cohenk(column1, column2, group, usemissing)
Parameter | Description |
|---|---|
column1 | The first attribute you want to use in the function. The column1 parameter is mandatory. |
column2 | The second attribute you want to use in the function. The column2 parameter is mandatory. |
group | The attribute by which you want to further group results. |
usemissing | A Boolean which indicates whether missing values should be considered or not in the computation of the statistics. The default value, if not otherwise specified, is True. |
Example
The following example uses the Bike sales dataset.
Description | Screenshot |
|---|---|
In the example here, we want to retrieve the Cohen K coefficient from the relationship between the Cost and the Revenue. We type the following formula: | 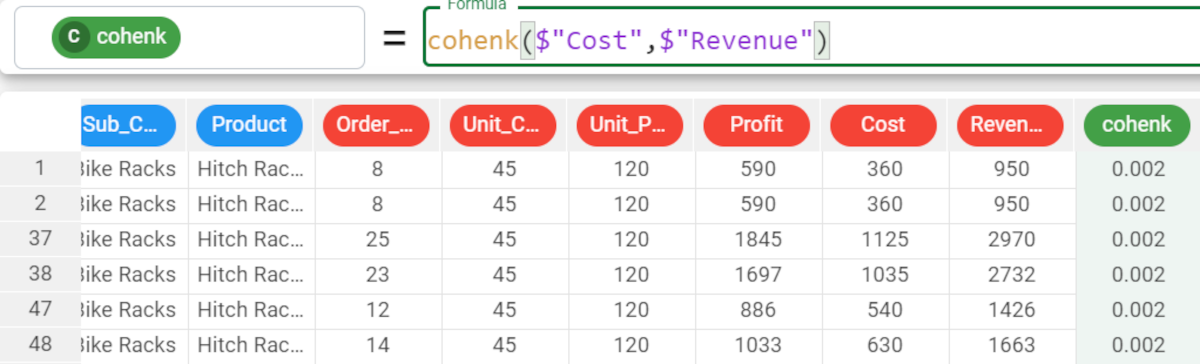 |
If we want to focus our analysis on certain groups, we simply need to add the group parameter. For example, we want to calculate the Cohen K coefficient between the Cost and Revenue attributes, grouping our results by the Country attribute, and we want the string NONE to be displayed if in any of the first two columns there are some missing values. The formula to write will be: The results are:
and so on. | 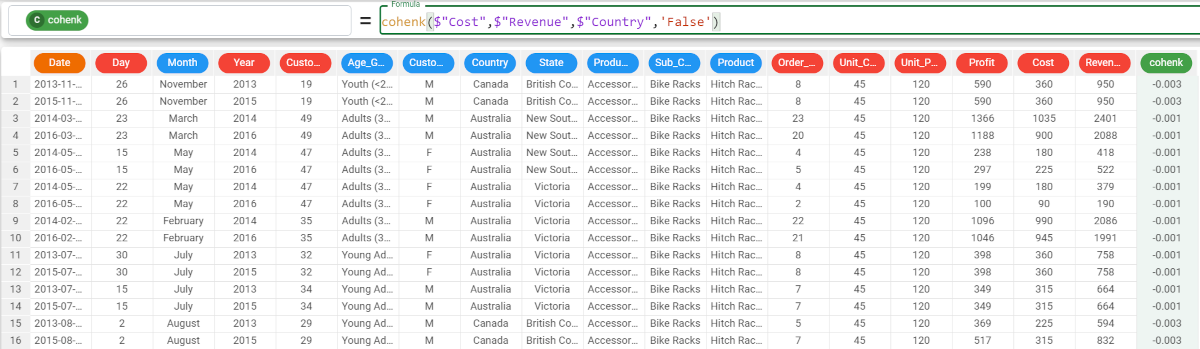 |