discEqualFrequency function in the Factory
The discEqualFrequency function discretizes data values into bins which contain the same number of values in each.
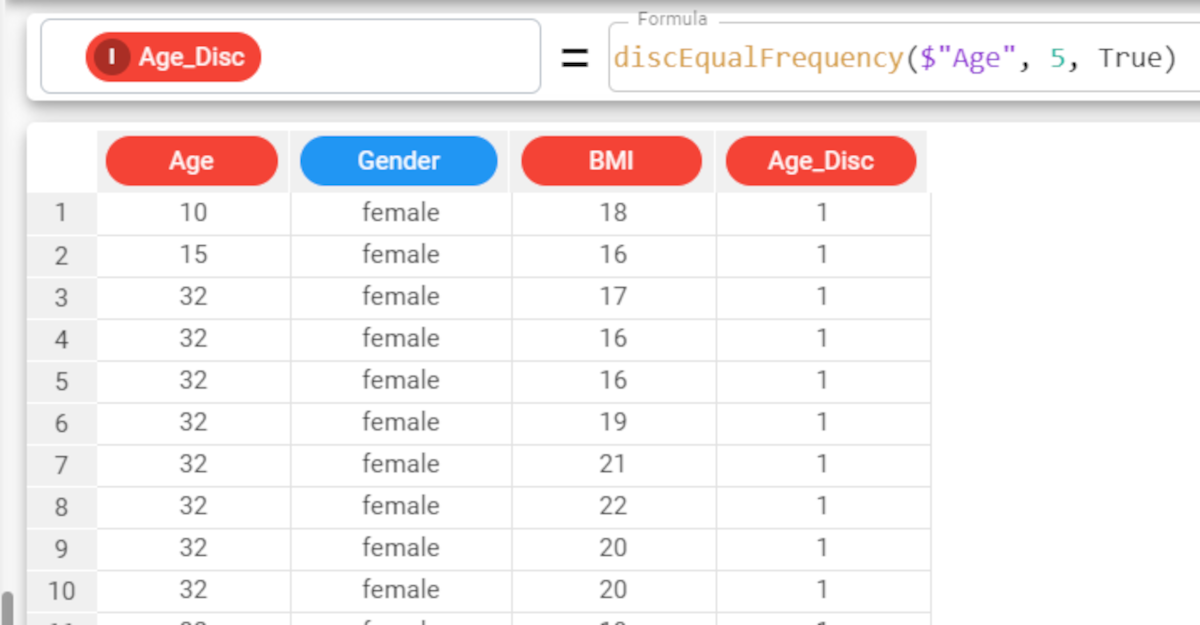
Parameters Parameter Description column The attribute whose values we want to discretize. The column parameter is mandatory. nvalue The number of bins you want to create. Cutoff values will be automatically created to discretize values into ranges. All cutoff points must be enclosed in square brackets. The nvalue parameter is mandatory. rank By default, the central value of each range is displayed. If instead we want to display a ranking number for each range, the rank value must be set to True. It is False by default. quantile If set to True, the values will be discretized in quantiles. By default, this parameter is set to False. This option has a particular impact when there are many identical values in a dataset. Standard discretization will put identical values in a single bin, and perform discretization on the remaining values, while if the quantile parameter is used, multiple bins may have the same central value, if this value is found in a high percentage of rows in the dataset. Example The following example uses the Age_BMI dataset. This dataset has been extracted from the public Hepatitis C Virus (HCV) for Egyptian patients dataset available on Kaggle. Description Screenshot In the Age_BMI dataset, we have added a new attribute, called Disc_Age, to the dataset to contain the discretized values of the Age attribute. In this new attribute we have divided the Age values into 5 different bins, which each contain the same number of values, with the formula The resulting 5 groups display the central value for each bin: 35, 40, 46, 52, 58. If we want to display a ranking number for each range, we simply set the rank parameter to True, instead of leaving its default value. The formula will consequently be: The resulting 5 bins will now have a ranking number from 1 to 5.discEqualFrequency(column, nvalue, rank, quantile)discEqualFrequency($"Age", 5).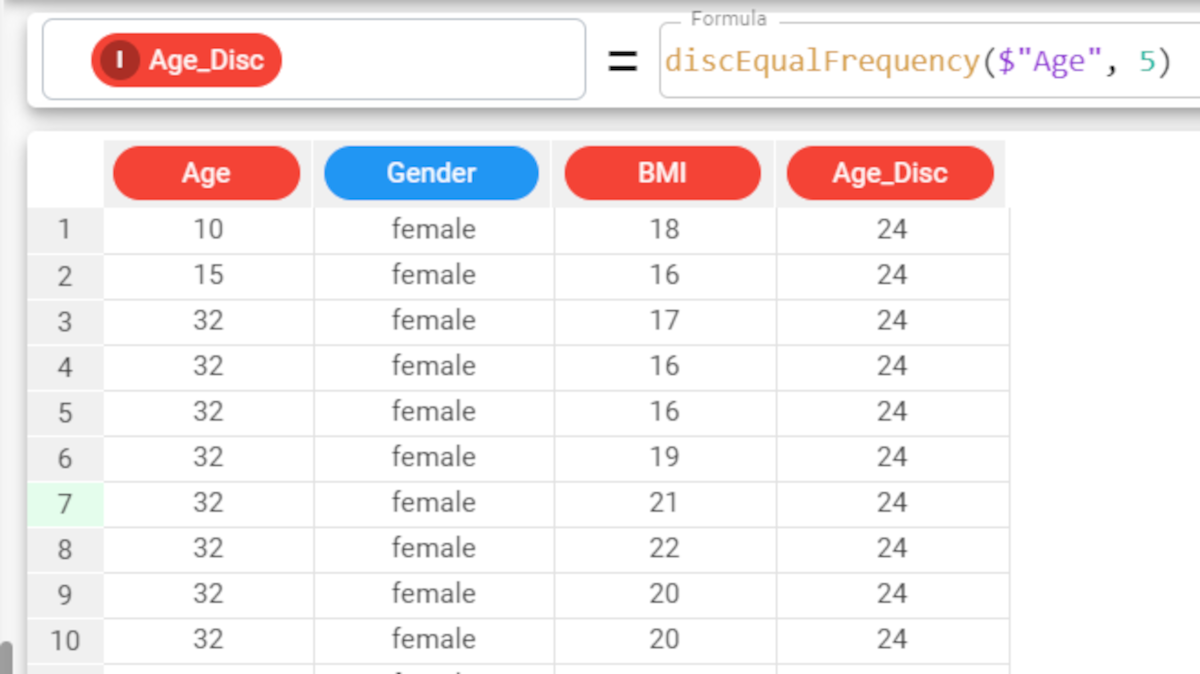
discEqualFrequency($"Age", 5, True).